

「開発したシステムが遅い!」と感じた時の対応策とは?社内システム、業務システムの場合は?

目次[非表示]
- 1.なぜ、あなたの開発したシステムが遅いのか?
- 1.1.社内システムが遅い場合
- 1.2.基幹システムが遅い場合
- 2.システムが遅い原因とは?
- 2.1.知っておきたいシステム開発の流れ
- 2.2.感覚的に「遅い!」と言われたら確認すべき事
- 2.3.ロジックが重い、エラーで動かない場合
- 3.システムが遅い時の対策の具体的な進め方
- 3.1.性能改善の最初の対策(インフラ側)
- 3.1.1.計測して、改善する事を繰り返すのが基本
- 3.2.現状の監視と計測について
- 3.3.即効性のある対策はあるのか
- 3.4.少ない改修で対応可能なインフラ側の手立てまとめ
- 4.本質的な改善のためのアプリケーション側の対策
- 4.1.スケールアウトの準備で見落としがちなポイント
- 4.2.セッション情報の管理での注意点(スティッキーセッション)
- 4.2.1.おすすめのロードバランサ
- 4.3.ロジックのボトルネックを探る
- 4.4.単体テストの有無とその効果
- 5.まとめ
開発したシステムが遅いと感じる場合、その原因はさまざまな要素からなることがあります。機能要件を満たすことに注力し過ぎていると、非機能要件であるパフォーマンス面が後回しになりがちです。こうした状況を放置すると、ユーザーの利用満足度が低下し、ビジネスに大きな影響を与える可能性があります。
本記事では、まずシステムが遅くなる原因を整理し、インフラ面とアプリケーション面の両側から具体的な対策方法を解説します。原因をしっかり把握しないまま改善を試みると、結果的に時間やコストだけがかかり、根本的な解決が得られないケースが多いので注意が必要です。
ネットワーク環境やハードウェア構成の再点検、また負荷試験やプロファイリングによるボトルネック箇所の可視化は、現状を客観的に把握する上で重要です。これらの方法で明確化した問題点に対して、効率よく改善策を打ち出す手順を順を追って解説していきます。
なぜ、あなたの開発したシステムが遅いのか?
・・・・悩める孤独な担当者Aの独り言・・・
担当者A:「こんな課題を解決するシステムが作りたい。こういう機能でこういう画面で、クラウドでホストしてモダンなフレームワークでやっていこう。」
担当者A:「オフショア開発でチームに仕様を伝えていれば、想像していたよりサクサク動くものが出来てくる。しかも安い!いいね!」
担当者A:「スモールスタートでローンチしてどうか・・・」
担当者A:「なんてこった、遅い!というクレームがユーザから結構くる。変なエラーメッセージが出てきたという問合せもあった。開発中は特に問題を感じなかったけど、ユーザが使い始めたら確かに色々モッサリしてきている気がする。」
担当者A:「さてどうしたものか……。」
このように、開発した後に問題が明らかになったシステムの性能問題について取り扱うことが弊社でも増えてきました。おそらく開発に関わるポストにいれば、少なからずこういった場面に直面する経験があるのでは無いでしょうか。
システムが遅い要因を把握するためには、どの部分で遅延が発生しているのかを整理することが大切です。
システムが遅く感じられる要因は、ハードウェアのスペック不足だけではありません。例えば接続するネットワーク環境に問題があったり、思わぬ箇所のロジックが重くなり過ぎていたりと、複数の要素が絡み合っている場合がほとんどです。特に非機能要件のすり合わせが十分行われていないプロジェクトでは、この問題が後から顕在化し、対応が後手に回ることもあります。数値化や可視化が不十分なままでは、根本原因を特定しにくく、対策の優先順位も定まりにくい点に留意が必要です。
この記事ではシステムの性能問題についての取り組みを、具体的な情報や事例を挙げながら情報共有していこうと思います。
■関連記事:
社内システムが遅い場合
社内で利用しているシステムが遅く感じられる場合、まずはネットワーク環境の品質を確認しましょう。LANケーブルやHUBの故障、無線LANの帯域不足などが原因となっているケースも少なくありません。多くの社員が同時にアクセスすることで想定以上の負荷がかかり、処理が遅延する場面も考えられます。
また、社内専用システム同士の連携が複雑化していると、余計な中継処理が増えてレスポンスが遅くなることがあります。特にレガシーな連携方式を使っている場合は、処理の流れを最適化できるかどうかを検討するだけでも、体感速度が大きく改善する可能性があります。管理体制の見直しや可視化ツールの導入などで、遅延発生ポイントをはっきりさせてから対策を進めるとよいでしょう。
基幹システムが遅い場合
基幹システムでは大規模なデータベースへアクセスする機会が多いため、高い負荷がかかりやすいです。データベース側でインデックスが適切に貼られていなかったり、テーブルが肥大化して最適化されていないと、クエリ処理だけで時間を要してしまいます。レガシーシステムとの接続が残っている場合は、データ変換やフォーマット変換が余計な処理時間を生み出す点にも注意が必要です。
加えて、基幹システムは信頼性を重視するあまり、頻繁にアップデートやパフォーマンス監視を行わずに使い続けられるケースがあります。長期稼働の結果、メモリリークやディスク容量逼迫などの物理的な問題を放置していると、システム速度が大幅に低下する可能性があります。定期的なメンテナンスと最適化を実行し、実際の負荷状況に合わせて構成を見直すことが重要です
システムが遅い原因とは?
開発プロセスの初期段階から、どこにボトルネックが生じやすいかを意識することで、大幅な速度低下を未然に防げます。
システムが遅いと一概にいっても、その症状や原因は開発の各プロセスに紐づいています。例えば、要件定義時にパフォーマンス要件を細かく洗い出さないまま機能開発を優先すると、後から最適化を行う際に大規模な変更が必要になるケースがあります。一方で、実際の運用段階になってユーザーからの苦情で初めて遅さに気付くことも珍しくありません。
こうした事態を回避するためには、運用開始後も含めて計測と監視を継続的に行い、どのように負荷が推移していくかを見極める必要があります。特に、トラブルが起きていない平常時にも試験的に負荷をかけ、余裕を把握しておくことで、突発的なトラフィック増にも柔軟に対応できるようになります。
知っておきたいシステム開発の流れ
システム開発において、開発を請け負う立場としては基本的に以下の流れで進めます。
- 要件定義
- 仕様設計
- 実装
- テスト
- 受入・導入
この最初の「要件定義」は、実は詳細を詰めると「ビジネス要件」と「ユーザ・業務要件」とに分けられることが多いのです。
ルーチンとしては、まずビジネス要件があり、それを実現するためのユーザ(業務)要件があって、ユーザ要件を実現するために必要なシステム要件に落とし込まれて設計→実装→テストと進んで行きます。開発の進め方がアジャイルであっても、この流れが小刻みになるだけで、本質的には変わりません。
この中で、ビジネス要件というのは本来、性能やセキュリティと言った非機能要件を多く含み、ユーザ・業務要件は機能要件を多く含みます。
そしてエンジニア側視点でシステム開発を進めていく際には機能要件を最初に考え、非機能要件と呼ばれる実体の無い要件は後回しにされがちです。
そんな状態で「機能」が開発されて動くようになり、テスト環境で触ってみても何の問題も無さそうだと思っても、いざローンチして運用を始めると、ユーザやデータが増えてきたときに「遅くて使い物にならない!」という悲鳴を聞くことはとても多いのです。
▼システム開発の工程は、こちらを参考にしてみてください。
→システム開発の工程と4つの手法|開発コストを抑える方法も解説
感覚的に「遅い!」と言われたら確認すべき事
上司や、クライアントから感覚的にシステムが「遅い!」と言われたことはありませんか?
感覚的に「遅い!」と言われても、指標が無ければ現場としてはどこから手を付ければ良いのか分かりません。とはいえ性能指標について決めるにしても、初めての場合は妥当な数値を出すのも難しいものです。そこで、まずは現状を数値化して、客観的に見られるようにするのが先決です。
性能テストも他のテストと同様ですが、実際に利用されている環境とほぼ同じ環境であることは非常に重要です。特にデータ量については遅いと言われている環境と同じにしなければ正確なテストが出来ません。
「負荷が集中している時に遅いのか」、「データ量が多い時に遅いのか」、注文する立場からすれば「とにかくあらゆる状況を想定してテストして欲しい」と言いたいところですが、一刻も早く是正したい時ほど、現状を正確に把握して優先順位を決めるのはとても重要になります。
まずはどこが遅いのかを可視化すべきです。
よく使われるのはNew RelicやDynatraceといったサーバにエージェントを仕込んで全てのトラフィックをモニタリングするツール群や、想定したシナリオでJmeterを動かしてシステム全体の機能を舐めるのも良いでしょう。ただし、Jmeterの場合は、作り手が考えたシナリオでしかないため、実際のユーザはあまり使わない機能が含まれる事もあり、優先順位を決める際にノイズとなってしまう事もある点は認識しておきましょう。
逆に稼働中のサーバに仕込むNew Relicなどのツールの場合は、まだ起きてない状況をシミュレートすることは当然出来ません。
要するに、どちらが良いという話では無く、状況に応じて適したものを選ぶ、もしくは両方使えばよいということです。
指標として、プロダクトの責任者と共通認識を持っておきたいのは以下の2点です。
- 同時接続数
- データ量
どんなにデータ量が少なくても同時接続数が多ければ極端に遅い、というケースの場合、サーバをスケールアップすることで解決してしまえることもあります。もちろん、ピークに合わせてスケールを決めてしまうとコスト的な無駄が増えるので最適解では無いのですが、根本解決までの時間稼ぎにはなります。
こんなとき、クラウドならサーバのスペックはすぐに変えられるので本当に便利です。
ロジックが重い、エラーで動かない場合
システム全体で重い部分が見えてきたら、詳しく分析してみましょう。
PHPであればBlackfireが便利です。一昔前なら自分でxdebugやwebgrind等を入れて可視化していましたが、それに比べると大分楽ですし、フレームグラフもとても見やすいので本当にオススメです。
アンチパターンでは無いので見過ごし後から発見されやすいのは、大量のデータを繰り返し処理するような部分です。
数百件のデータをforループで繰り返しながら、その内側でDBアクセスが発生し数千回のSQLクエリが発行されているというのは初心者に多く見られがちです。確かにプログラミングは簡単なので、とりあえずの実装としては致し方ない部分はあります。
※ データを一括で取得してメモリに保持するという方法が良いとは限らないのでアンチパターンとは言い切れません。
この辺、例えばORマッパーの性質をよく知ってないと全く予想していないクエリの出し方をしたりするので、自分たちの使っているライブラリがどういうものなのかを深く理解するのは本当に大切です。
開発時のテストでは全く問題が無いですが、本番ではすぐに再現するというケースも良くあります。色々な原因は考えられますが、まずはデータを問題が発生しているサーバと同じ状態にしてみると、大体は再現できます。
その他にも、最近のWebアプリケーションエンジニアはサーバ側のことを意識しなくて済むようになっている場合もあるので気付きにくいこともありますが、「同時に開けるファイル数」がシステムにはパラメータとして存在しており、ファイルの閉じ忘れによって上限を超えてしまい、リソースはスカスカなのにエラーになる、という状況も見かけます。
これはプロファイリングツールでは分からないので、エラーログを注意深く見ていくことで発見できます。これは遅いというケースでは無いですが、遅さを調べる過程でこのような問題が見つかる場合も多いです。
■関連記事:
システムが遅い時の対策の具体的な進め方
ここまでは性能についての問題が発覚するまでの大まかな流れを見てきました。
では、次に実際どうやって進めたら良いのか?について具体的な作業の進め方を紹介していきたいと思います。
まずは、性能改善の最初の対策として弊社でもよくあるインフラ側の手立てについてご紹介します。
性能改善の最初の対策(インフラ側)
前項でシステム開発のよくある流れについて確認しました。
<遅い!→調べた!→とりあえずサーバは強化しておこう→駄目なコード××!>
少し整理すると、性能改善のためにやるべき事は概ね以下になります。
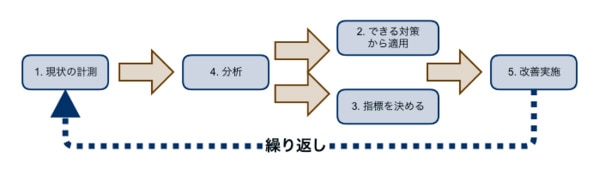
- 現在の状況を監視・計測して事実を認識する
→New Relicを仕込んだり、JMeterで負荷をシミュレートしたりして問題箇所を探る。 - 即効性のある対策で時間稼ぎをしつつ、根本解決に向けた改善活動を進める
→スケールアップやインスタンスタイプの変更、スケールアウトできるならサーバ台数の調整等を行う。 - 性能目標値を決める
→ユーザ数、データ量の増加傾向について試算し、機能毎に重要度・緊急度から優先順位を付けて改善活動のガイドとなる考え方をまとめておく。 - 分析してボトルネックを探す
- プログラムに問題がある場合、New RelicやBlackfireといったプロファイリングツールを駆使してボトルネックを分析する。
- あらゆる手段で性能改善を行う
→ロジックに改善の余地が無くても、要件を阻害しない範囲で仕様の見直しを含めた対策をひねり出す。
一先ずこの流れを一通り行えばOKなのですが、これでは表面的な説明だけで「あるある!」と多少の共感を得るだけで終わってしまいます。
そこはもう一歩踏み込んでおきましょう。
計測して、改善する事を繰り返すのが基本
開発チームが計測と改善も両方やるのであれば、ボトルネックに対する心当たりがあるのは自然なことです。その時も計測する前に直して感覚的に早くなった、というのはあまりオススメできません。慌てずエビデンスを残しながら進めて行く事が重要であると考えましょう。
余談ですが、一般的に開発に費やす時間よりも、システムが稼働し続けそれを保守し続けることの方がはるかに長いものです。
その過程では、開発した人と保守する人が違うという状況は当然のようにあります。
問題となっている部分の原因を調査するとき、何故そうしたのかという理由や経緯が追跡できることはチームのモチベーションにも影響し、ひいてはサービスの信頼性を維持向上するために重要なポイントです。
現状の監視と計測について
ひとまず遅いと指摘を受けてしまった場合は、まずその指摘箇所から調査を進めることになるでしょう。弊社ではオープンソースのプロダクトを利用することが多く、負荷テストにはApache JMeterを使うことが多いです。
「Apache JMeter」は無料なのに十分な機能性があり、基本的な負荷テストはこれだけで用が足りることも多いです。
しかし、JMeterは負荷をかけることと、そのサーバからのレスポンスがどうかを計測するのが主な機能です。これだけでは、そのシステムのどのモジュールが遅いのかまでは分かりません。DB、IO、ネットワーク、アプリのどれが重いのかはまでは分からないのです。
そこで、前述でも軽く触れたNew RelicやBlackfireを利用することで、どの部分が遅いのかを一目瞭然で調べることが出来ます。
一昔前のWebアプリケーションやWeb APIだけで見ればサーバサイドのレスポンスタイムを計測するだけで足りる場合もありますが、昨今のWebアプリケーションについてはReal User Monitoring(RUM)と呼ばれるように実際のユーザが体感している速度を計測して、ユーザ満足度を指標化していこうとする動きがあります。
New Relicは、その点を強めに押し出しているように見えますが、実際問題、現代のWebアプリケーションではサーバ側だけが高速であっても、ブラウザ側の処理が遅くモッサリしているというのもしばしば耳にします。
エンドユーザが遅いと感じる原因を考えると、影響のある要素としては以下のものがあります。
- クライアントPCの性能
- JavaScriptの処理性能
- サービスとユーザ間のネットワーク
- サーバのロジック性能
- クエリの性能
- DBの性能
- 各サーバのIO
これらの全てを計測し判断材料となる情報を提供してくれるAPMツールを選定することは非常に重要なポイントです。

即効性のある対策はあるのか
例えば、JMeterで負荷をかけてみたところ、スレッド数(同時接続ユーザ数)が50を超えた辺りで著しくレスポンスタイムが遅くなることが発覚したとします。
ここで、サービスのオーナー(お客様)と決めなければならないのは以下の2点です。
- 想定すべき同時接続数
- レスポンスタイムの許容時間
例えば50名が同時アクセスで5秒以内に応答が無ければならない、という目標値となります。
こうしたとき、改善手段としては
- サーバをスケールアップする
- スケールアウトできるようにアプリケーションを改修する
- ロジックの性能を改善する
クラウド環境であれば、スケールアップするのが最もコストのかからない対策となる事が多いです。
ただ、例えば以下の様な条件があるかも知れません。
▶️同時接続数が50近くなるような時間帯は1日の中でも夜8時〜9時の間
この場合、スケールアップして凌ぐことが出来たとしても、コスト的には最適では無いといえます。同時利用者数が少ない時間帯はオーバースペックとなってしまうためです。
ピーク時間帯が予想できるのであれば、該当時間帯にスケールアウトするようにオートスケールを構成すれば中長期的にはコストメリットが出てくるでしょう。
オートスケールにした場合、アプリケーションのセッション管理をファイルで行っているならば、セッション情報をフロント側で共有する必要があるため、MemcacheやRedisといったキャッシュサーバを使うように構成変更しなければなりません。そして、その場合はアプリケーション側でも少なくとも設定変更とテストが必要になります。
少ない改修で対応可能なインフラ側の手立てまとめ
これまでの簡単なまとめをすると、比較的少ない改修で対応可能なインフラ側の手立てとして、以下の流れで対策を打てることが多いです。
- スケールアップしてサービスが止まらないようにする
- スケールアウトできる構造にアプリケーションを改修する
- オートスケールにする
しかしながら、本質的にはアプリケーション自体をスリムにしていかなければならない事は忘れないでください。
インフラ側で手を打つというのは、「太ったから着る服のサイズをワンサイズ上げた」と言う意味に近いからです。
つまり根本的には体を絞って健康にならなければならない、ということです。
本質的な改善のためのアプリケーション側の対策
これまでに性能改善の最初の対策として弊社でも良くあるインフラ側の手立てについてご紹介しました。
実際に本質的な改善をするにあたって、アプリケーション側をどのように対策していくのか、最も実践的な部分を説明していきます。
スケールアウトの準備で見落としがちなポイント
まず、スケールアウト【 scale out 】 とは、コンピュータシステムの性能を増強する手法の一つで、システムを構成するサーバーの台数を増やすことで、システムの処理能力を高めることをいいます。
何らかのトラブルでサーバーが故障しても別のサーバーでカバーできるため、システムの可用性が高まり安定運用が可能となり、処理を並列化、分散化できるシステムで主に適用されます。例えば、Webサーバーのように主にWriteではなくReadが多いシステムにおいて、数多くのアクセスを分散処理で対応するような場合、サーバーの台数を増やすスケールアウトが適しています。
一方、巨大なデータベースへのアクセス速度を向上させるには、サーバー同士の連携が必要になるため、単にサーバー数を増やすスケールアウトでは、あまり効果が見込めないので注意が必要です。 ロジックの改善についてお話しする前に、前述で「インフラ側の改善に関わる部分」について説明しきれていなかったのでここで取り上げておこうと思います。
APサーバとDBサーバから構成されるシステムにおいては、ユーザからのアクセスを受け付けるAPサーバを複数台並べ、ロードバランサで負荷分散および可用性の向上を図る構成が一般的とされています。
ロードバランサの役割としては、【1】システムに対するリクエストを複数のサーバに分散させ、処理のバランスを調整し、【2】メンテナンス時には切り離し可の仕組みで、ロードバランサを導入することにより、スケーラビリティ(拡張性)とアベイラビリティ(可用性)などを実現することができます。
セッション情報の管理での注意点(スティッキーセッション)
ログインなどをさせるサイトになってくるとユーザーのセッション情報を保持させなくてはなりません。 サーバをスケールアウトする際、ロードバランサー側のセッション単位でサーバを固定する設定にしていない場合は、アプリケーション側の対応が必要となります。ロードバランサー側ではスティッキーセッションなどと呼ばれたりします。
例えばAWSではApplication Load Balancer(ALB)を使っている場合はこれが使えます。
AWSのロードバランサーの種類としては、ELB (Classic Load Balancer)、ALB (Application Load Balancer)、NLB (Network Load Balancer)となり、Network Load Balancer(NLB)を使っている場合はこの機能が無いため、ユーザのリクエストをどのサーバに飛ばすかを固定できません。
単一のサーバーでサービスを行っている場合は特に問題にはなりませんが、複数のサーバーでアクセスを受けるとなるとセッションの情報は共通で持っておく必要があります。
PHPでは、通常の設定ではセッション情報はファイルとしてサーバに保存されています。従って、リクエストのたびに処理するサーバが変わってしまうと、セッションを維持できないということになります。よって、セッション情報はLocalで保存される形式を使用するのではなく外部に保存するようにすると良いでしょう。
大抵のアプリケーションフレームワークは、セッションをファイル以外の場所に保存する事が出来るので、どのサーバからも参照できる場所(データベースやキャッシュサーバ)に保存する様なイメージで設定変更すれば良いです。
おすすめのロードバランサ
上述の補足ですが、個人的におすすめなロードバランサをご紹介しておきます。目的に合わせて選択すると良いでしょう。
- ALB(Application Load Balancer):
HTTP トラフィックおよび HTTPS トラフィックの負荷分散に最適なロードバランサ。Webサイトのロードバランサとして使用するのであれば、このロードバランサがおすすめです。 - NLB(Network Load Balancer):
TCPトラフィックなどネットワーク系の負荷分散に最適なロードバランサ。 - ELB(Classic Load Balancer):
複数のAmazon EC2インスタンスにおける基本的な負荷分散を行うのに最適なロードバランサ。
ロジックのボトルネックを探る
そもそも、APMとは、主に企業の基幹システムなどを担うWebアプリケーションのレスポンス状況を監視、様々な機能の応答時間を調べることによって、アプリケーション全体の稼働状況を管理するシステムをいいます。
APMを導入により、レスポンス遅延などアプリケーションの不具合を予兆の段階で察知し、障害の発生を未然に防ぐことが可能となり、実際に問題が生じた場合、調査時間を削減するメリットがあります。
これらアプリケーションに対して管理者が直面する課題として下記のことが挙げられます。よって下記の条件を満たすツール選びが必須となります。
- アプリケーションの使用状況やステータスを忠実に可視化
- パフォーマンスのボトルネックであるJ2EEやJavaコンポーネントの特定
- アプリケーションの遅延の原因であるSQLクエリの特定と、JVM パフォーマンスの監視
- 優れたユーザーエクスペリエンスを提供するための、最適なアプリケーションのトラブルシューティング
BlackfireやNew Relic、AppDynamicsといったAPM(アプリケーション性能管理)ツールを使ってどのように問題点を探り、どのような改善をするかが重要です。
①重いメソッドを探る
↓
②重い原因を探る(多すぎる繰り返し処理)
↓
③クエリの最適化
↓
④アーキテクチャ変更を伴うか?難しい決断
単体テストの有無とその効果
性能改善のコード修正は機能に影響を及ぼしてはなりません。その際に単体テストがあれば、安心して性能改善のリファクタリングを進めることが出来ます。この段階で単体テストの有無がジワジワ効いてくることでしょう。
普通のプロジェクトでは、機能面の改修は日々行われているはずですが、そんな中で性能改善のコードをマージするとなると、場合によっては色々な影響を及ぼすことになります。よってリリース計画は慎重に行う必要があります。
■関連記事:
まとめ
この記事では「あなたの開発したシステムがなぜ遅いのか、遅いと言われずにリリースするにはどうしたらよいか?」についてご紹介してきました。
開発後に問題が明らかになるシステムの性能問題について、頭を抱える開発エンジニアは多いでしょう。 もっとも、性能やセキュリティといった非機能要件を開発フェーズで意識するのとしないのとでは結果は全く異なってきます。
問題が発生した際には、まずはどこが遅いのかを可視化するためにNew RelicやDynatraceなどのツールを用いて現状を正確に把握し、JMeterで負荷をシミュレートして問題箇所を探ります。ここから先は、優先順位を決めて冷静に対処していくことです。
よく感覚的に「遅い!」と言われる場面がありますが、指標が無ければ現場としてはどこから手を付ければ良いのか悩むだけなので、性能目標値を決めていきましょう。
システム全体で重い部分が見えてきたら、Blackfireなどのプロファイリングツールを用いて詳しく分析しましょう。その後は、要件を阻害しない範囲で解決策をひねり出すしかありません。 文字だけで見ると、簡単なように見えてしまいますが、かなり根気のいる作業です。
弊社コウェルでは2007年の創立以来、多くのオフショア開発における品質保証支援を行ってきました。
これまでに様々なオフショア開発での品質課題を解決するなかで蓄積したノウハウや方法論をベースに、オフショア開発に加えソフトウェアテストのご支援もさせていただいております。
特にオフショア開発における品質面においてお悩みや課題を抱えられている方は、ぜひ一度コウェルにご相談ください。
コウェルに関する詳細資料は以下でダウンロードすることが可能です。また、具体的なご相談がございましたら、以下のお問い合わせからもお気軽にご連絡ください。









